Turn Your Data into a Strategic Asset – Big Data & Data Lake Experts
Build scalable, secure, AI-ready data lakes and lakehouses that deliver real-time insights and 10× faster decisions.












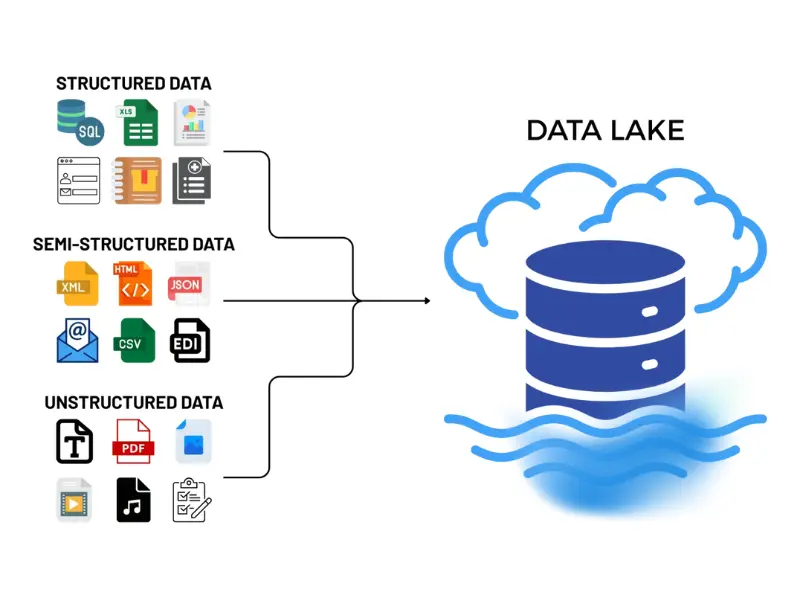
Is Unmanaged Data Slowing Your Business Down?
Most companies globaly struggle with:
You’re sitting on petabytes of gold — but can’t mine it.
We Build Enterprise-Grade, AI-Ready Data Lakes
All your data at one place. Zero headaches.
Store Everything
Raw files, logs, JSON, video, IoT at petabyte scale
Govern Once, Use Everywhere
Unified security, lineage & catalog
Query 10× Faster
With Apache Iceberg, Trino, Spark & Oracle Autonomous
Fuel AI & Analytics
Direct access for Data Science, BI, and GenAI
End-to-End Big Data & Data Lake Services
Data Lake Strategy & Roadmap
Custom architecture tailored to your industry
Cloud & On-Prem Data Lake Build
Oracle OCI ∙ AWS ∙ Azure ∙ Hybrid
Real-Time Ingestion & Streaming
Kafka ∙ Flink ∙ GoldenGate ∙ NiFi
Governance, Security & Compliance
Ranger ∙ Unity Catalog ∙ Fine-grained policies
Advanced Analytics & BI
Looker ∙ Power BI ∙ Oracle Analytics ∙ Custom Dashboards
AI/ML Integration & Model Deployment
Direct training on lake data – no copying
Powered by the Best-in-Class Ecosystem







Real Results for Pakistani & Global Companies

Leading Textile Group (Karachi)

Top Private Bank (Lahore)
